In this post I shall show how to scrape Texas covid data and create animated plots. The purpose is to demonstrate how this can all be done seamlessly with R, without the need to download or manually edit the excel files in any way.
Texas covid data is stored at this website. For this post we will focus on the link “Cases over Time by County”. This link leads to an excel sheet with covid cases by county. Unfortunately, like many excel files, it is filled with random text that isn’t data - e.g. titles, notes etc. We will need to edit the file before working with the data.
Importing the Data
To directly import an excel file that lives at a web link we need the RCurl package. We download the file into a temporary location (our working directory), and then we read that with read_xlsx() from the readxl package. Because I’m using a Windows machine, I need to include , mode = "wb" at the end of the download.file() function. If you’re on a different operating system, you could delete this bit.
library(RCurl)
library(readxl)
# for Windows, mode = 'wb'
download.file("https://dshs.texas.gov/coronavirus/TexasCOVID19DailyCountyCaseCountData.xlsx", "temp.xlsx", mode = "wb")
tmp <- read_xlsx("temp.xlsx")Cleaning the Data
We have our excel file imported as a dataframe in R called tmp. Let’s look at its size, and then we’ll look at the first 5 rows and 4 columns:
dim(tmp)
[1] 267 230
tmp[1:5, 1:4]
# A tibble: 5 x 4
`COVID-19 Total Cases b~ ...2 ...3 ...4
<chr> <chr> <chr> <chr>
1 DISCLAIMER: All data ar~ <NA> <NA> <NA>
2 County Name "Cases \r\r\r~ "Cases \r\r\r~ "Cases \r\r\~
3 Anderson "0.0" "0.0" "0.0"
4 Andrews "0.0" "0.0" "0.0"
5 Angelina "0.0" "0.0" "0.0" As you can see, the top of the dataframe is messy. The colnames are nonsensical. The first row is also not related to anything we need. The second row appears to have something of value. It appears that the third row is when our county names and data begin.
Let’s look at the second row in more detail. We can look at the first three entries:
as.character(tmp[2,1:3])
[1] "County Name"
[2] "Cases \r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\n\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\n03-04"
[3] "Cases \r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\n\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\n03-05"The first entry is what should be the column name of column 1 - the county name. The other entries have a lot of random text (a remnant of some excel formatting) and some numbers at the end. Indeed, the last five characters refer to the date. If we grab the last five characters of each entry in this row, we will have our dates. When doing this, I also noticed that two dates (July 15th and July 17th) had asterisks at the end also. This is because down at the bottom of the excel book there were footnotes relating to these dates - some extra data were included on these dates.
We can grab all the dates by getting the last 5 characters (using str_sub() from stringr) and ignoring asterisks (using gsub() - and we have to do \\* to make sure that it really knows we mean asterisks. We’ll make these our new column names:
colnames(tmp) <- stringr::str_sub(gsub("\\*", "", tmp[2,]),-5)We can now get rid of the nonsense top two rows, and take a look at our data:
tmp <- tmp[-c(1:2),]
tmp[1:5, 1:4]
# A tibble: 5 x 4
` Name` `03-04` `03-05` `03-06`
<chr> <chr> <chr> <chr>
1 Anderson 0.0 0.0 0.0
2 Andrews 0.0 0.0 0.0
3 Angelina 0.0 0.0 0.0
4 Aransas 0.0 0.0 0.0
5 Archer 0.0 0.0 0.0 These excel worksheets often have garbage at the bottom of the data - let’s check this:
tmp[250:nrow(tmp), 1:3]
# A tibble: 16 x 3
` Name` `03-04` `03-05`
<chr> <chr> <chr>
1 "Wood" 0.0 0.0
2 "Yoakum" 0.0 0.0
3 "Young" 0.0 0.0
4 "Zapata" 0.0 0.0
5 "Zavala" 0.0 0.0
6 "Total" 0.0 0.0
7 <NA> <NA> <NA>
8 "Counties Reporting Cases" 0.0 0.0
9 <NA> <NA> <NA>
10 "Notes:\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\r\~ <NA> <NA>
11 "Case counts do not include probable cases" <NA> <NA>
12 "County-level case counts were not available on Ma~ <NA> <NA>
13 "Population data is based on Texas population proj~ <NA> <NA>
14 "* Texas is reporting 10,791 new confirmed COVID-1~ <NA> <NA>
15 "** Texas is reporting 10,256 new confirmed COVID-~ <NA> <NA>
16 <NA> <NA> <NA> It looks like after the county Zavala, we have several rows of stuff we don’t need. These are totals, sub-totals and footnotes. As we want to make this code reproducible - and the authors of the excel sheet may add more footnotes in the future - we’ll tell R to locate ‘Zavala’ and cut-off the datasheet there. We’ll also call the dataframe df as it’s now clean:
df <- tmp[1:which(tmp[,1]=="Zavala"),]
df[1:5,1:4]
# A tibble: 5 x 4
` Name` `03-04` `03-05` `03-06`
<chr> <chr> <chr> <chr>
1 Anderson 0.0 0.0 0.0
2 Andrews 0.0 0.0 0.0
3 Angelina 0.0 0.0 0.0
4 Aransas 0.0 0.0 0.0
5 Archer 0.0 0.0 0.0 The final thing we’d like to do to help with plotting and summary stats, is to conver this dataset from wide to long.
We’ll also make the first column name say ‘county’ and make sure the format of the date, and the value (number of Covid cases) are correct:
library(tidyverse)
df.long <- df %>% pivot_longer(2:ncol(df), names_to = "date")
colnames(df.long)[1]<-"county"
df.long$date <- as.Date(df.long$date, format = "%m-%d")
df.long$value <- as.numeric(df.long$value)
head(df.long)
# A tibble: 6 x 3
county date value
<chr> <date> <dbl>
1 Anderson 2020-03-04 0
2 Anderson 2020-03-05 0
3 Anderson 2020-03-06 0
4 Anderson 2020-03-09 0
5 Anderson 2020-03-10 0
6 Anderson 2020-03-11 0
tail(df.long)
# A tibble: 6 x 3
county date value
<chr> <date> <dbl>
1 Zavala 2020-10-16 419
2 Zavala 2020-10-17 436
3 Zavala 2020-10-18 436
4 Zavala 2020-10-19 438
5 Zavala 2020-10-20 443
6 Zavala 2020-10-21 452Visualizing
For a first plot, we’ll use tidyverse to count up all the covid cases on each day for all counties of Texas. Then we’ll plot those data as a line graph. We’re using scales here to make sure the y-axis has readable numbers:
library(scales)
df.long %>%
group_by(date) %>%
summarise(total = sum(value)) %>%
ggplot(aes(x=date, y = total)) +
geom_line(color="#123abc", lwd=1) +
theme_classic() +
scale_y_continuous(labels = comma_format()) +
ylab("Total Cases") +
xlab("") +
ggtitle("Number of Covid Cases in Texas 2020") +
theme(axis.title = element_text(size=16))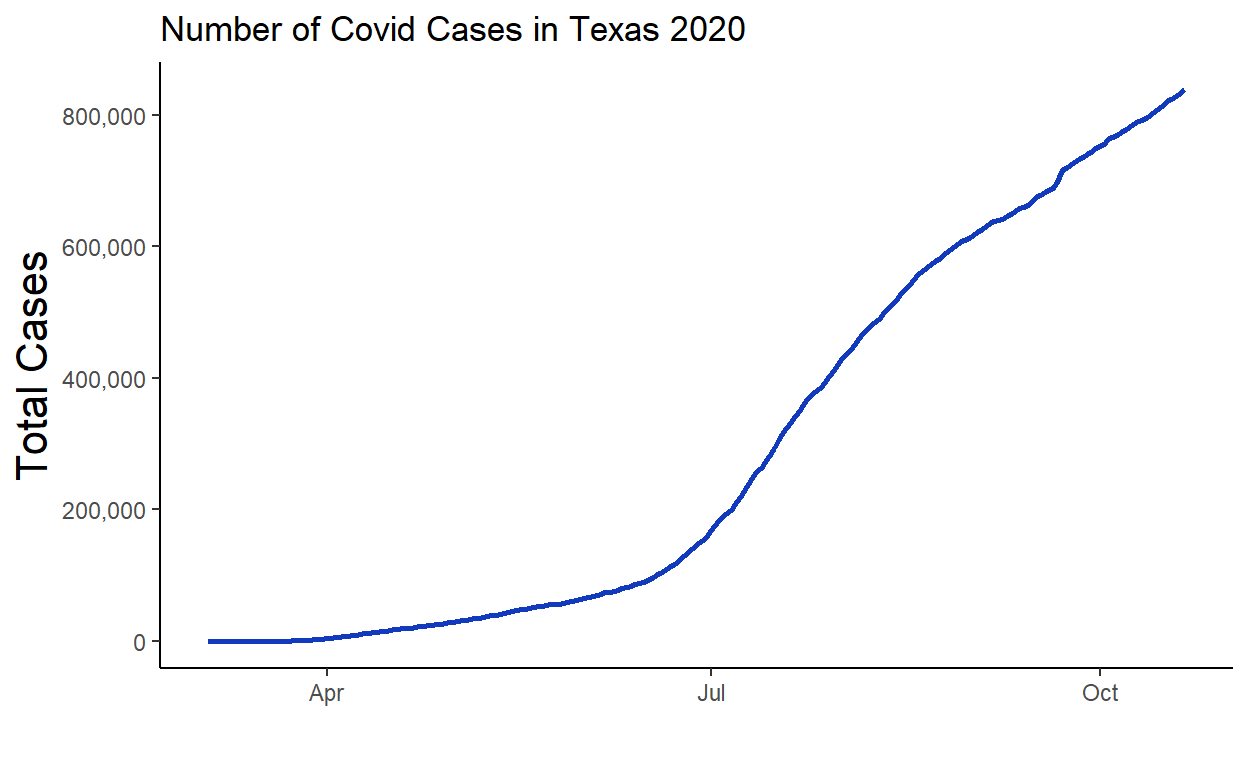
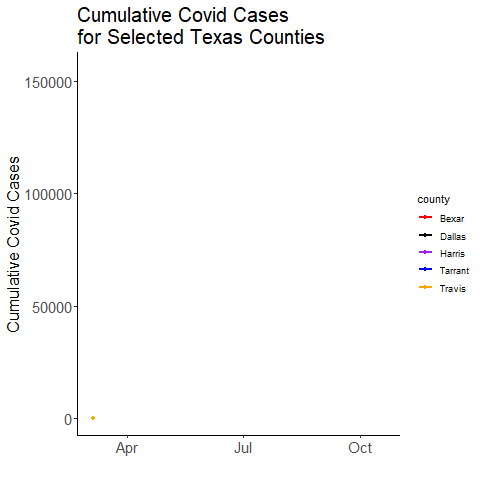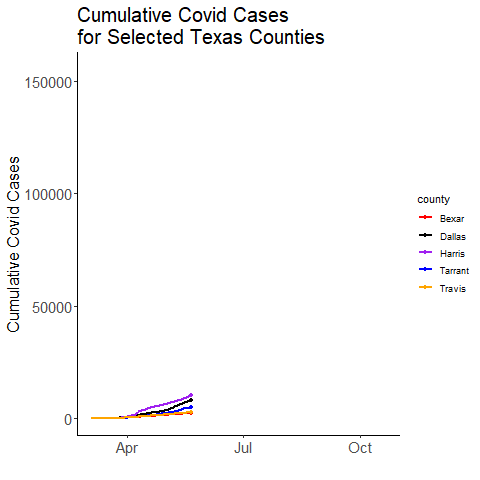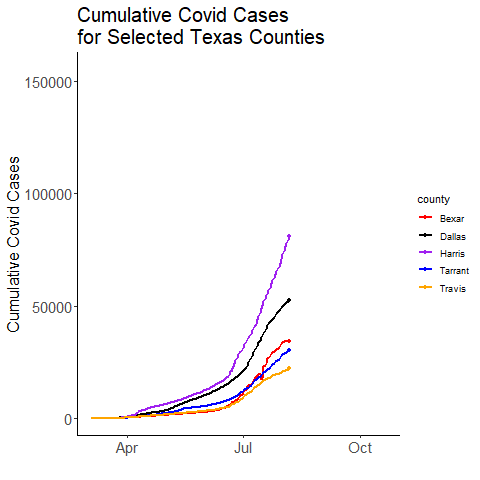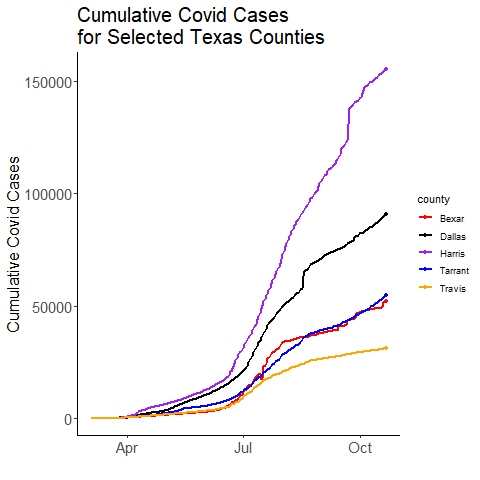
Now we are going to set ourselves the task of animating the Covid cases over time. We don’t want to do it for all 254 counties, so we will pick the five counties that have the most cases. We’ll use tidyverse to group by county to find the total cases per county:
# let's pick the five highest counties.
df.long %>%
group_by(county) %>%
summarise(total = sum(value)) %>%
arrange(-total)
# A tibble: 254 x 2
county total
<chr> <dbl>
1 Harris 12165234
2 Dallas 7825756
3 Tarrant 4406921
4 Bexar 4321739
5 Travis 2962018
6 Hidalgo 2644776
7 El Paso 2333416
8 Cameron 1924428
9 Fort Bend 1489174
10 Nueces 1436065
# ... with 244 more rowsWe can now grab the five counties with the most cases, and then filter our long dataframe to only include those counties using %in%:
# we can automatically grab these like this:
df.long %>%
group_by(county) %>%
summarise(total = sum(value)) %>%
arrange(-total) %>%
.$county %>%
head(5) -> my_counties
my_counties
[1] "Harris" "Dallas" "Tarrant" "Bexar" "Travis"
#only keep data with these
df.long %>%
filter(county %in% my_counties) -> df.x
head(df.x)
# A tibble: 6 x 3
county date value
<chr> <date> <dbl>
1 Bexar 2020-03-04 0
2 Bexar 2020-03-05 0
3 Bexar 2020-03-06 0
4 Bexar 2020-03-09 0
5 Bexar 2020-03-10 0
6 Bexar 2020-03-11 0
tail(df.x)
# A tibble: 6 x 3
county date value
<chr> <date> <dbl>
1 Travis 2020-10-16 30688
2 Travis 2020-10-17 30797
3 Travis 2020-10-18 30908
4 Travis 2020-10-19 30956
5 Travis 2020-10-20 31053
6 Travis 2020-10-21 31159Now to animate. We will use the gganimate package. This should work “out-of-the-box”, however, you may need to also install the av or gifski packages to ensure that it doesn’t just make hundreds of still images, but instead compiles them into an animation. The only bit of code we need to add to an otherwise static plot is the line + transition_reveal(date) which means we are animating along our x-axis (date). We use anim_save() to save the animation
# May take a few seconds
ggplot(df.x, aes(x=date, y=value, color=county)) +
geom_line(lwd=1) +
geom_point() +
scale_color_manual(values=c("red", "black", "purple", "blue","orange"))+
ggtitle("Cumulative Covid Cases \n for Selected Texas Counties") +
theme_classic() +
ylab("Cumulative Covid Cases") +
xlab("")+
theme(
axis.title = element_text(size=16),
plot.title = element_text(size=20)
)+
transition_reveal(date)
# Save as a gif:
anim_save("covid.gif")