The babynames package put together by Hadley Wickham is a lot of fun for teaching R. This package contains a dataset of the same name that contains the number of boys and girls born each year since 1880 with every name.
What you’ll notice if you play around with graphing the distribution of children born with particular names is that there are different patterns. Some names were popular long ago, some are only popular recently, others have had ups and downs in popularity. For a bit of fun, I thought it would be interesting to try and identify different patterns through principal components analysis (PCA) and clustering techniques.
Let’s load the libraries we’ll need and the data:
### load packages
library(babynames)
library(gridExtra)
library(tidyverse)
library(colorspace)
library(tsne)
head(babynames)
# A tibble: 6 x 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Mary 7065 0.0724
2 1880 F Anna 2604 0.0267
3 1880 F Emma 2003 0.0205
4 1880 F Elizabeth 1939 0.0199
5 1880 F Minnie 1746 0.0179
6 1880 F Margaret 1578 0.0162
tail(babynames)
# A tibble: 6 x 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 2017 M Zyhier 5 0.00000255
2 2017 M Zykai 5 0.00000255
3 2017 M Zykeem 5 0.00000255
4 2017 M Zylin 5 0.00000255
5 2017 M Zylis 5 0.00000255
6 2017 M Zyrie 5 0.00000255As can be seen, this dataset records the number of children (n) of each name (name) that are boys or girls (sex) that were born in each year (year). The data go from 1880-2017. Additionally, the proportion (prop) of children born with that name in each year.
To plot the pattern of an individual name over time, I’m going to write a little custom function:
# Function to plot a name over time
plot_name <- function(bname = NULL) {
babynames %>%
filter(name==bname) %>%
ggplot(aes(year, n)) +
geom_line(aes(color=sex), lwd=1) +
scale_color_manual(values = c("firebrick1", "dodgerblue")) +
theme_bw() +
ggtitle(bname)
}
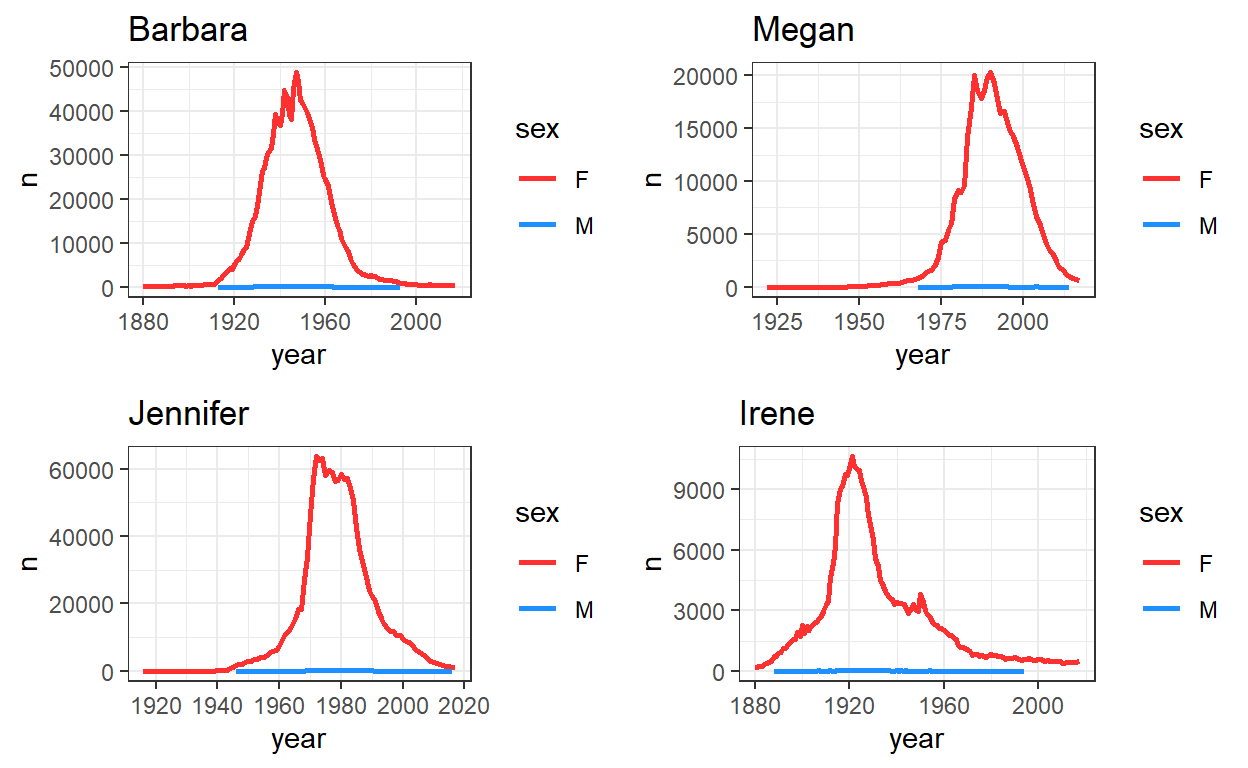
grid.arrange(
plot_name("Barbara"),
plot_name("Megan"),
plot_name("Jennifer"),
plot_name("Irene"),
ncol=2
)
We’ll just focus on female names. These are the most popular female names of all time:
babynames %>%
filter(sex == "F") %>%
group_by(name) %>%
summarize(total = sum(n)) %>%
arrange(-total)
# A tibble: 67,046 x 2
name total
<chr> <int>
1 Mary 4123200
2 Elizabeth 1629679
3 Patricia 1571692
4 Jennifer 1466281
5 Linda 1452249
6 Barbara 1434060
7 Margaret 1246649
8 Susan 1121440
9 Dorothy 1107096
10 Sarah 1073895
# ... with 67,036 more rowsWe can also see that there are 67,046 unique female names in the dataset. Here are some of the least common names:
babynames %>%
filter(sex == "F") %>%
group_by(name) %>%
summarize(total = sum(n)) %>%
arrange(total)
# A tibble: 67,046 x 2
name total
<chr> <int>
1 Aada 5
2 Aaden 5
3 Aadilynn 5
4 Aafreen 5
5 Aagot 5
6 Aaheli 5
7 Aaiyana 5
8 Aaja 5
9 Aakira 5
10 Aakiyah 5
# ... with 67,036 more rowsIn fact there are 9,595 names that appear 5 times only in the dataset. To be entered into the data, each name must have been registered at least five times in a given year. So for all of these names, in one year there were five children born with that given name - and that was the only year.
babynames %>%
filter(sex == "F") %>%
group_by(name) %>%
summarize(total = sum(n)) %>%
filter(total==5) %>%
nrow()
[1] 9595For instance, the first name on the list - Aada - was given to five children in 2015:
babynames %>% filter(name == "Aada")
# A tibble: 1 x 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 2015 F Aada 5 0.00000257Reshape Data
The first exploration of these data that I’d like to do is to perform a PCA on the distribution of the frquency of names over years. This will give us a general idea of how many different ‘components/groups’ we might expect.
To do this, we need to have our data in a ‘wide’ format, with each column/variable representing a year and each row representing the total number of births that year for that particular name. We’ll put the names into rownames so we can keep that information, but only have numbers in the dataframe.
babywideF <-
babynames %>%
filter(sex=="F") %>%
select(name, year, n) %>%
pivot_wider(names_from = year, values_from = n, values_fill = list(n = 0))
rownames(babywideF)<- babywideF %>% .$name #set rownames
babywideF <- babywideF %>% select(-name) # remove name variableHere are the first 5 rows and 4 columns of the dataframe, as well as the rownames:
babywideF[1:5,1:4]
# A tibble: 5 x 4
`1880` `1881` `1882` `1883`
<int> <int> <int> <int>
1 7065 6919 8148 8012
2 2604 2698 3143 3306
3 2003 2034 2303 2367
4 1939 1852 2186 2255
5 1746 1653 2004 2035
rownames(babywideF)[1:5]
[1] "Mary" "Anna" "Emma" "Elizabeth" "Minnie" PCA
For this sort of exploratory analysis, I’m going to simply use the default PCA function in R - princomp() and plot scree plots.
### principal components analysis - females
resF.pca <- princomp(babywideF)
plot(resF.pca)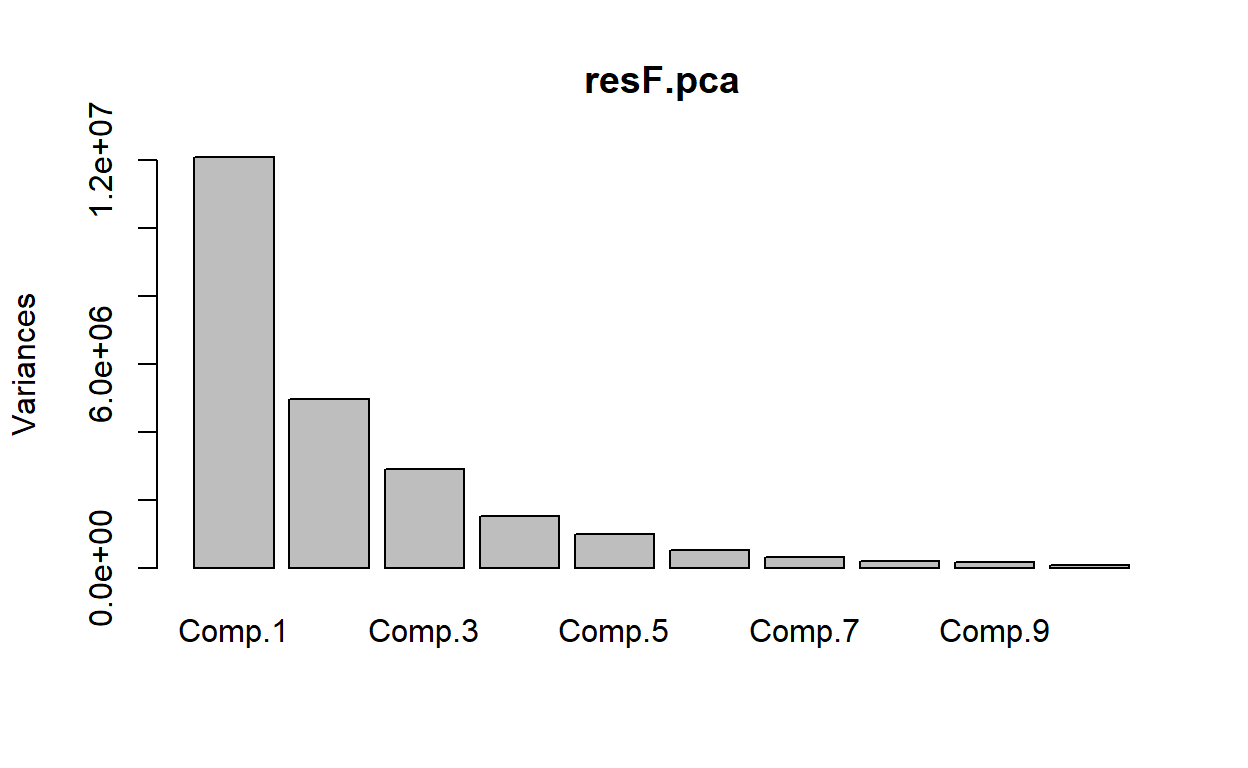
The above scree plot seems to indicate that there is one major component of names that accounts for the majority of variance. There then appears to be a few more components that account for a fair amount of variance. Depending on how micro-detailed we want to go, we could look for 4 or 5 components fairly reasonably. Though there may be something of interest in looking at 7 or 8 groups.
Clustering
To explore which names show more similar distribution patterns to one another over time, I’m going to firstly use k-means hierarchical clustering. There are pros and cons to all clustering methods. A problem with k-means is that you can get different clusters each time you run it due to how the method operates. An upside is that it is a fairly flexible method…
The clustering is done with the kmeans() function and by setting the number of clusters to find. After saving the results, we can look at how many individual names have been put into each cluster (the relative number of the cluster isn’t that important - e.g. if we re-run the clustering, the clusters with most names could be called by a different cluster number in future runs). I am going to set.seed() to make sure that this code is repeatable.
###k-means clustering analysis
set.seed(100)
resF.k <- kmeans(babywideF, 6)
table(resF.k$cluster)
1 2 3 4 5 6
14 19 71 15 119 66808 The majority of names (66,808) are contained within the 1st component. The other five components have a much more manageable number of names.
Let’s look at some of these names in more detail. We’ll start with the smallest cluster - remember, these are names that should show very similar trends over time in the frequency of births:
names(resF.k$cluster[resF.k$cluster==1])
[1] "Anna" "Margaret" "Alice" "Helen" "Frances" "Marie"
[7] "Ruth" "Virginia" "Mildred" "Evelyn" "Betty" "Dorothy"
[13] "Doris" "Shirley" This first group seems to make sense. You could well imagine someone called Mildred who had friends from her childhood called Dorothy and Betty.
The next smallest cluster has these names, which appear to be boomer-era names:
names(resF.k$cluster[resF.k$cluster==4])
[1] "Mary" "Nancy" "Susan" "Barbara" "Cynthia" "Linda"
[7] "Kathleen" "Donna" "Deborah" "Carol" "Karen" "Patricia"
[13] "Sharon" "Sandra" "Debra" Then we have this cluster, which look to be more children of the 1980s:
names(resF.k$cluster[resF.k$cluster==2])
[1] "Elizabeth" "Sarah" "Laura" "Amanda" "Rebecca"
[6] "Amy" "Christina" "Melissa" "Angela" "Jessica"
[11] "Lisa" "Stephanie" "Kelly" "Heather" "Michelle"
[16] "Jennifer" "Ashley" "Kimberly" "Nicole" The next biggest cluster are names that are more recent still:
names(resF.k$cluster[resF.k$cluster==3])
[1] "Emma" "Ella" "Grace" "Julia" "Katherine"
[6] "Caroline" "Katie" "Hannah" "Emily" "Rachel"
[11] "Sara" "Sophia" "Victoria" "Leah" "Isabella"
[16] "Olivia" "Madeline" "Samantha" "Chloe" "Molly"
[21] "Savannah" "Ava" "Abigail" "Amber" "Monica"
[26] "Natalie" "Alicia" "Courtney" "Andrea" "Crystal"
[31] "Jamie" "Melanie" "Sydney" "Erin" "Haley"
[36] "Gabrielle" "Alexandra" "Vanessa" "Cassandra" "Jasmine"
[41] "Allison" "Erica" "Chelsea" "Shannon" "Shelby"
[46] "Paige" "Jenna" "April" "Morgan" "Megan"
[51] "Lauren" "Lindsey" "Alexis" "Kayla" "Mia"
[56] "Brooke" "Danielle" "Kristen" "Tiffany" "Kelsey"
[61] "Jordan" "Alyssa" "Taylor" "Destiny" "Brianna"
[66] "Brittany" "Hailey" "Katelyn" "Madison" "Kaitlyn"
[71] "Mackenzie"Finally, we have a large cluster of 119 names. The relationship of these names to each other might take some more digging:
names(resF.k$cluster[resF.k$cluster==5])
[1] "Annie" "Clara" "Florence" "Martha" "Carrie"
[6] "Edith" "Rose" "Catherine" "Lillian" "Louise"
[11] "Ethel" "Eva" "Edna" "Josephine" "Ellen"
[16] "Charlotte" "Jane" "Irene" "Kathryn" "Esther"
[21] "Theresa" "Pauline" "Anne" "Ann" "Eleanor"
[26] "Maria" "Ruby" "Christine" "Sylvia" "Carolyn"
[31] "Sally" "Sue" "Jean" "Jeanette" "Lois"
[36] "Teresa" "Loretta" "Lucille" "Regina" "Roberta"
[41] "Norma" "Annette" "Janet" "Juanita" "Julie"
[46] "Vivian" "Gladys" "Rita" "Tina" "Anita"
[51] "Marjorie" "Bonnie" "June" "Dolores" "Peggy"
[56] "Connie" "Jeanne" "Joan" "Wanda" "Diana"
[61] "Marcia" "Paula" "Leslie" "Geraldine" "Debbie"
[66] "Phyllis" "Suzanne" "Elaine" "Judith" "Judy"
[71] "Lynn" "Thelma" "Audrey" "Gloria" "Gail"
[76] "Jo" "Rosemary" "Joyce" "Dana" "Eileen"
[81] "Lorraine" "Denise" "Laurie" "Valerie" "Tracy"
[86] "Beth" "Yvonne" "Cindy" "Dawn" "Joanne"
[91] "Renee" "Carla" "Jacqueline" "Joann" "Beverly"
[96] "Janice" "Pamela" "Maureen" "Darlene" "Brenda"
[101] "Diane" "Marilyn" "Colleen" "Robin" "Jill"
[106] "Sheila" "Vickie" "Cheryl" "Sherry" "Kathy"
[111] "Rhonda" "Vicki" "Kim" "Michele" "Cathy"
[116] "Wendy" "Terri" "Lori" "Tammy" Just for completeness, here is a random sample of 10 names from ‘cluster 6’. As can be seen, these tend to be uncommon names.
set.seed(17)
sample(names(resF.k$cluster[resF.k$cluster==6]),10)
[1] "Ronna" "Yaely" "Sarahmarie" "Kiyasha" "Norell"
[6] "Jaleeza" "Darlina" "Chari" "Kanaiya" "Sherridan" Repeat the Process?
It might be more beneficial to repeat this process, but exclude the less common names. To do this we will filter our data by not keeping any names that appear in cluster 6. This leaves us with 238 names.
group1x <- names(resF.k$cluster[resF.k$cluster<6])
length(group1x)
[1] 238We can only keep these names, and redo our PCA:
babywideF1 <- babywideF %>% filter(rownames(.) %in% group1x)
### principal components analysis - females
resF1.pca <- princomp(babywideF1)
plot(resF1.pca)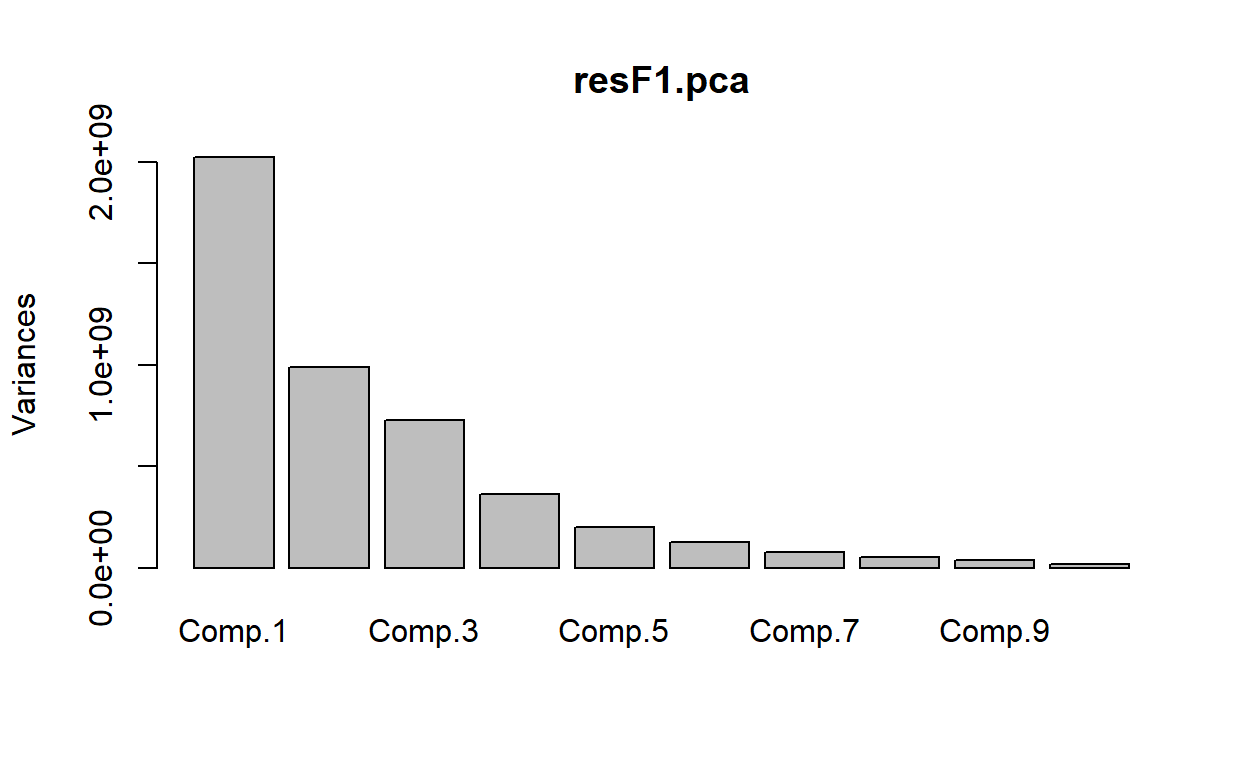
The scree plot again indicates approximately three or four main components, plus perhaps 3 or 4 ‘fringe’ ones. Let’s redo our K-means clustering with 7 clusters, just because it might be more fun/interesting to try and split names up as much as possible to see if it makes logical sense.
###k-means clustering analysis
set.seed(10)
resF1.k <- kmeans(babywideF1, 7)
table(resF1.k$cluster)
1 2 3 4 5 6 7
73 5 16 18 67 4 55 Again, let’s look at these in a bit more detail, this time looking from smallest group to largest. The first four appear to be older names. When we can compare their distributions on a plot, we can see that they are very similar having large peaks in the 1950s - although Mary also has a large peak in the 1920s:
babynames %>%
filter(sex=="F") %>%
filter(name %in% group1x[resF1.k$cluster==6]) %>%
ggplot(aes(year, n)) +
geom_line(aes(color=name, group=name), lwd=1) +
theme_classic() +
scale_color_discrete_qualitative(palette = "Dark 2")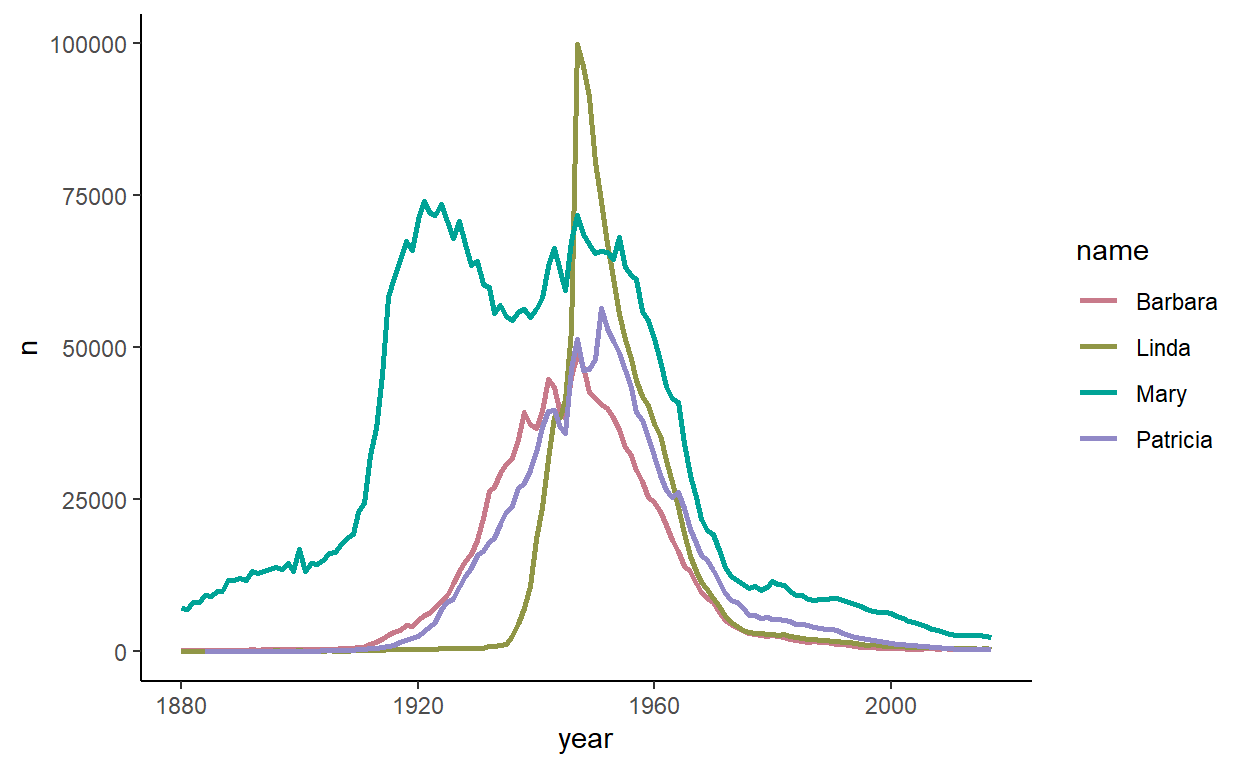
The next cluster of five names are even older names, all peaking in the 1920s:
babynames %>%
filter(sex=="F") %>%
filter(name %in% group1x[resF1.k$cluster==2]) %>%
ggplot(aes(year, n)) +
geom_line(aes(color=name, group=name), lwd=1) +
theme_classic() +
scale_color_discrete_qualitative(palette = "Dark 2")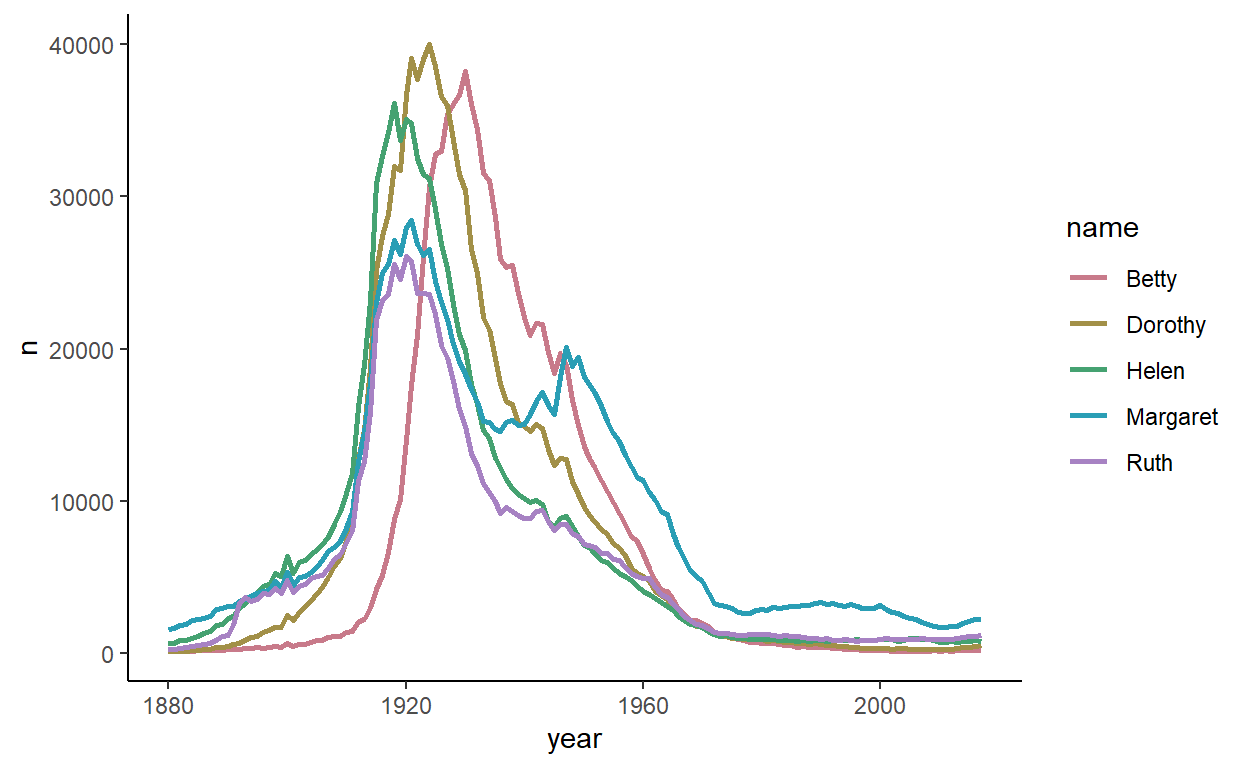
If I’m being picky, I would suggest that the peak of Betty is just after the other four names, and Margaret has a second peak in the 1950s. It’s possible we could find other names that match these patterns, but grouping these five together obviously has some merits.
The next group is cluster 3, which has 16 names - all very popular names during the 1950s & 1960s:
babynames %>%
filter(sex=="F") %>%
filter(name %in% group1x[resF1.k$cluster==3]) %>%
ggplot(aes(year, n)) +
geom_line(aes(color=name, group=name), alpha = .4) +
theme_classic() +
scale_color_discrete_qualitative(palette = "Harmonic")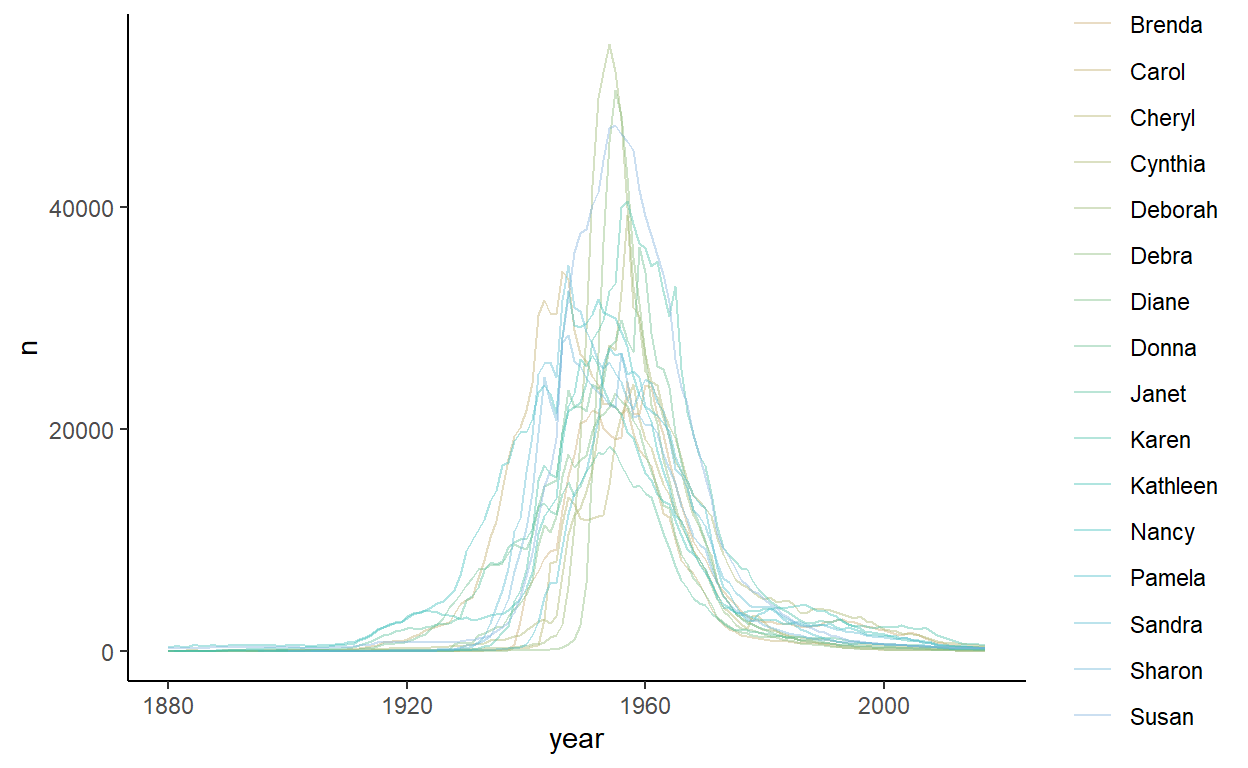
The next group is cluster 4, which has 18 names:
babynames %>%
filter(sex=="F") %>%
filter(name %in% group1x[resF1.k$cluster==4]) %>%
ggplot(aes(year, n)) +
geom_line(aes(color=name, group=name), alpha=.4) +
theme_classic() 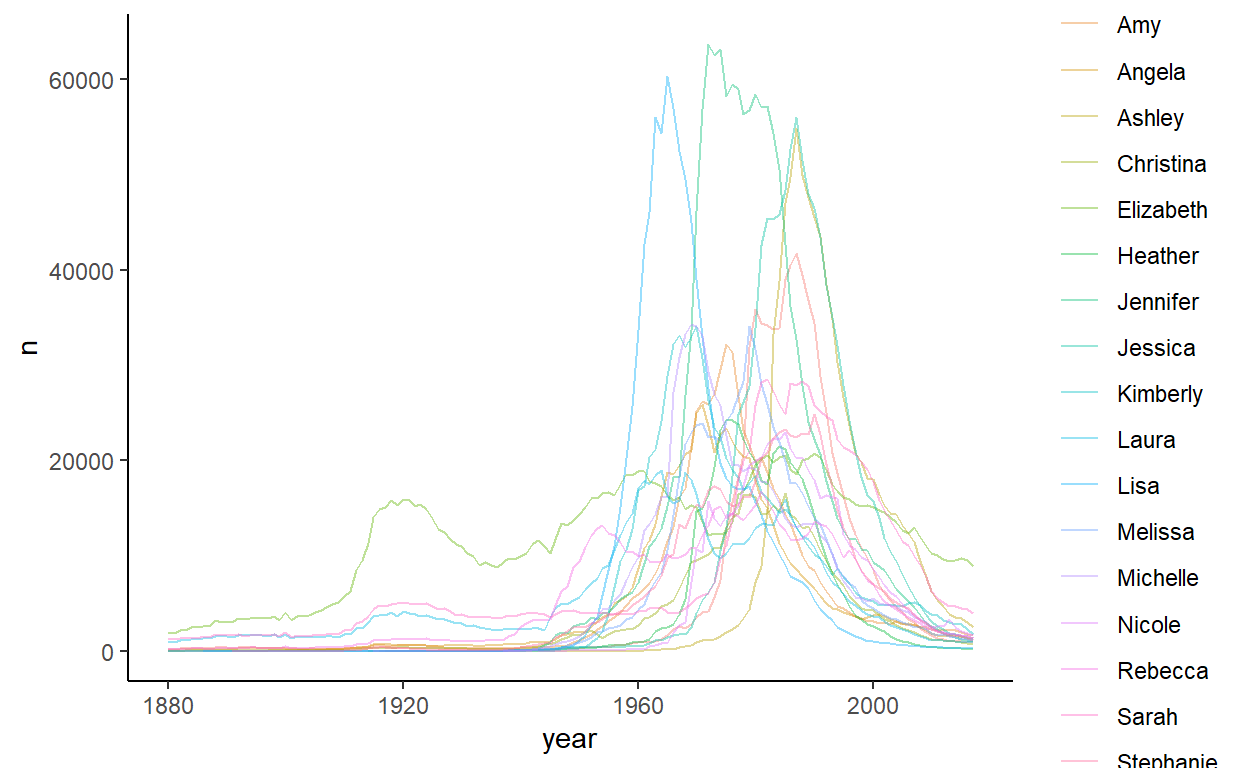
This group looks to be generally names that were popular during the 1970s and 1980s. However, there are a couple of names in here which look a bit out of place. The green line that has a large peak in the 1920s is Elizabeth. The blue line with a peak just after the 1960s is Lisa. The green line with the largest peak in the early 1970s is Jennifer. This name does have a similar pattern to the others - it’s just that it is so popular it has an elevated peak.
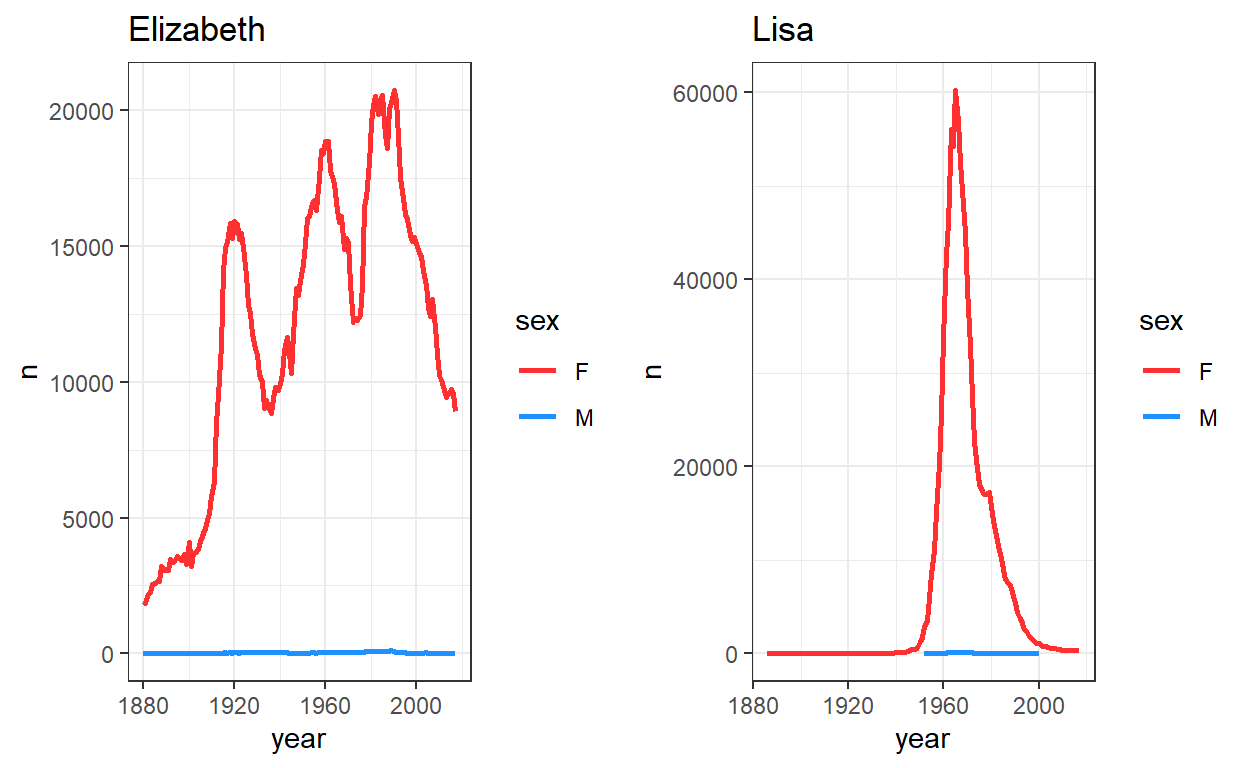
Here are Elizabeth and Lisa separated from the rest - Elizabeth is trimodal in its distribution having multiple periods of poularity!
grid.arrange(
plot_name("Elizabeth"),
plot_name("Lisa"),
ncol=2
)
The last three clusters - clusters 1, 5 and 7 have between 55-73 names each. Here, I’ll just plot each without showing the names.
Cluster 5 appears to include names from the 1990s, some having mini-peaks in the 1920s:
babynames %>%
filter(sex=="F") %>%
filter(name %in% group1x[resF1.k$cluster==5]) %>%
ggplot(aes(year, n)) +
geom_line(aes(group=name), color="#123abc", lwd=1, alpha=.2) +
theme_classic() +
theme(legend.position = 'none')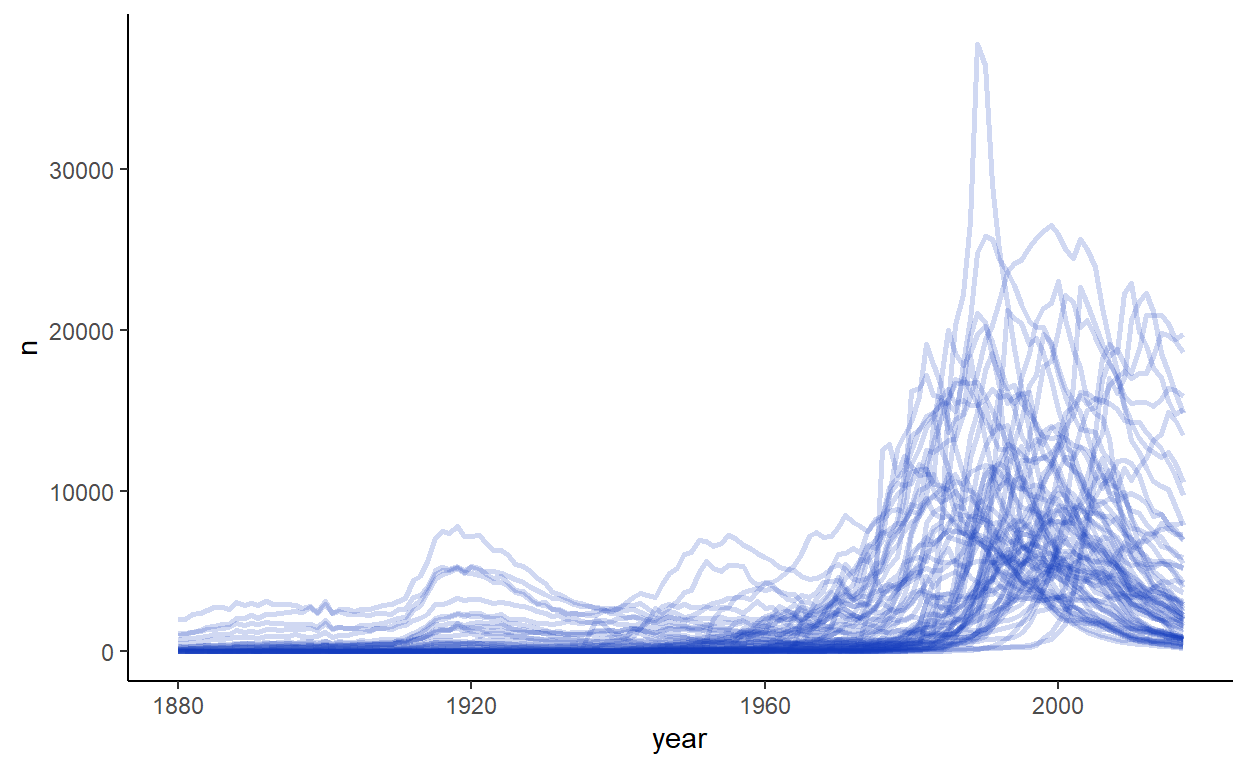
Three of the names that appear to have had the peaks in the 1920s as well as post 1990s are Ella, Grace and Julia:
babynames %>%
filter(sex=="F") %>%
filter(name=="Grace" | name=="Julia" | name=="Ella") %>%
ggplot(aes(year, n)) +
geom_line(aes(color=name), lwd=1) +
theme_classic()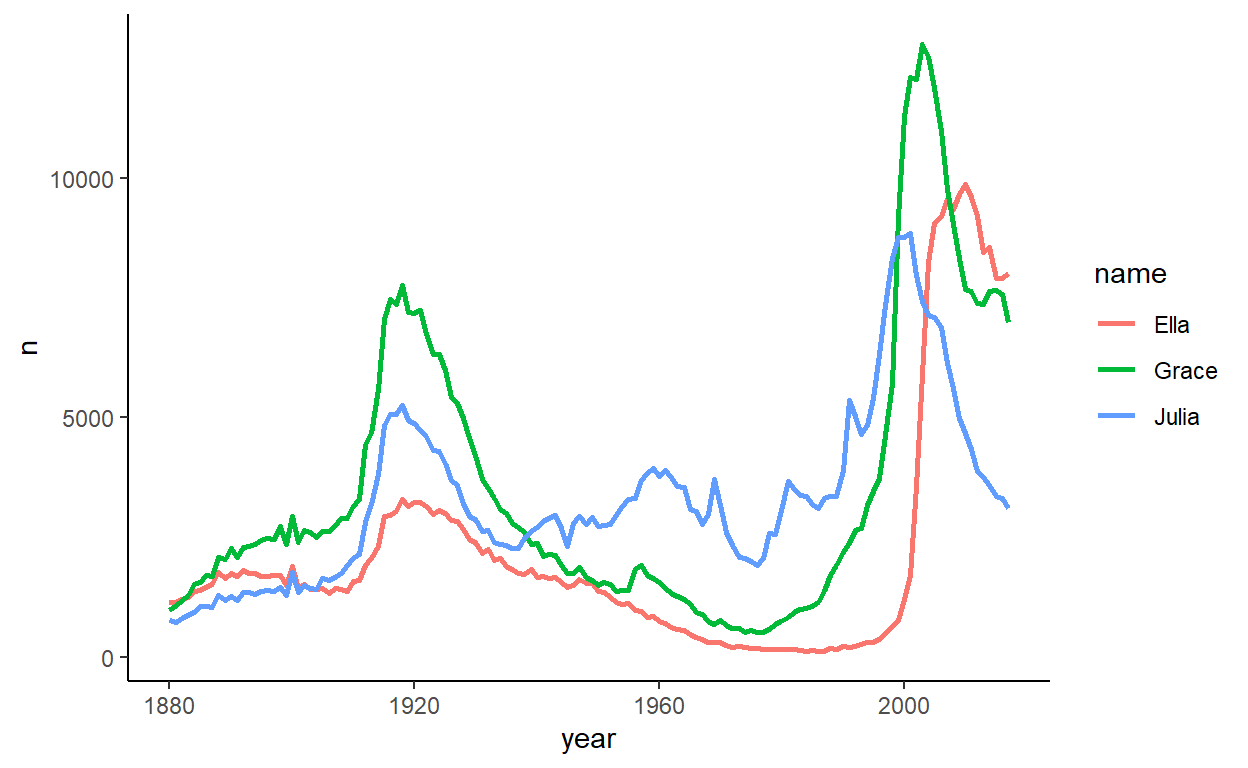
Cluster 7 appears to include names from the 1960s, being popular a litle after the boomers of cluster 3.
babynames %>%
filter(sex=="F") %>%
filter(name %in% group1x[resF1.k$cluster==7]) %>%
ggplot(aes(year, n)) +
geom_line(aes(group=name), color="lightseagreen", lwd=1, alpha=.2) +
theme_classic() +
theme(legend.position = 'none')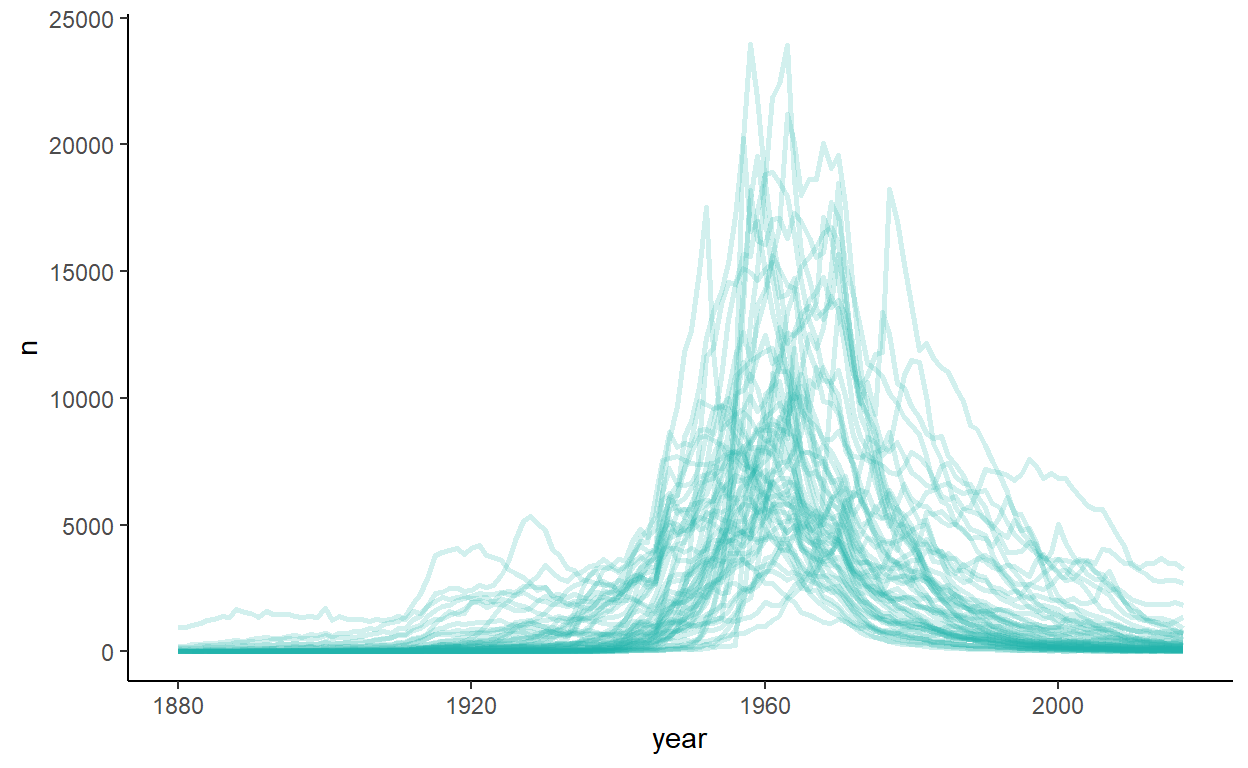
Cluster 1 is a little more mixed. There are clearly some 1920s names in here, but also possibly some other pre WW2 popular names.
babynames %>%
filter(sex=="F") %>%
filter(name %in% group1x[resF1.k$cluster==1]) %>%
ggplot(aes(year, n)) +
geom_line(aes(group=name), color="orange", lwd=1, alpha=.2) +
theme_classic() +
theme(legend.position = 'none')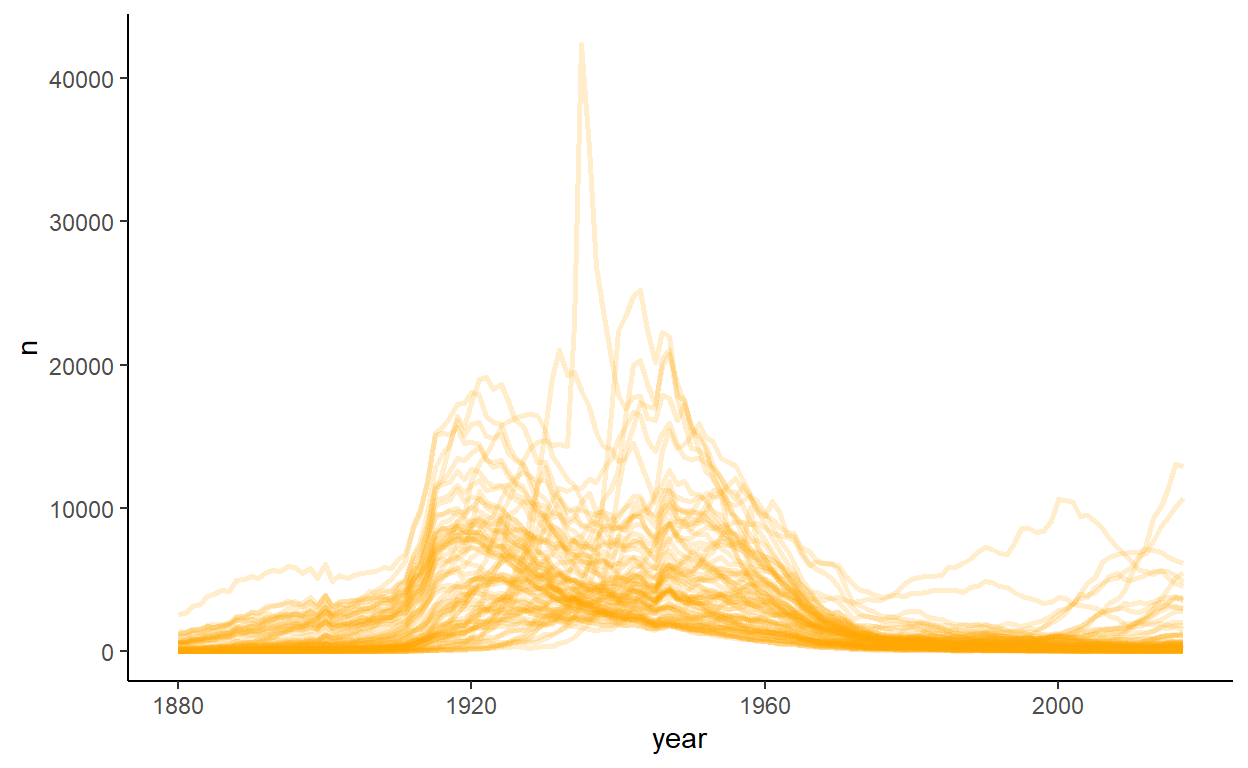
TSNE mapping
An intriguing way of mapping multidimensional data into a 2d plot is to use T-distributed Stochastic Neighbor Embedding. This can be done in the R package tsne.
Below I create a distance object, D, on which we will run the tsne analysis. I also create a dataframe to store the names, cluster id, and final coordinates of each name.
D <- dist(babywideF1) #create distance object
# creating dataframe for plotting colors and text on final plot
cluster1 <- group1x[resF1.k$cluster==1]
cluster2 <- group1x[resF1.k$cluster==2]
cluster3 <- group1x[resF1.k$cluster==3]
cluster4 <- group1x[resF1.k$cluster==4]
cluster5 <- group1x[resF1.k$cluster==5]
cluster6 <- group1x[resF1.k$cluster==6]
cluster7 <- group1x[resF1.k$cluster==7]
namesdf <- data.frame(
name = c(cluster1, cluster2, cluster3, cluster4,
cluster5, cluster6, cluster7),
group = c(rep(1, length(cluster1)),
rep(2, length(cluster2)),
rep(3, length(cluster3)),
rep(4, length(cluster4)),
rep(5, length(cluster5)),
rep(6, length(cluster6)),
rep(7, length(cluster7)))
)
namesdf <- namesdf[match(group1x, namesdf$name),] #names in correct order to match rownames of babywideF1
colors = rainbow(7)
names(colors) = unique(namesdf$group)
#define function used in plotting
ecb = function(x,y){ plot(x,t='n'); text(x,labels=rownames(babywideF1), col=colors[namesdf$group], cex=1) }
set.seed(100)
tsne_D <- tsne(D, k=2, epoch_callback = ecb, perplexity=50)We can add the output of tsne into the dataframe:
namesdf$x <- tsne_D[,1]
namesdf$y <- tsne_D[,2]
head(namesdf)
name group x y
180 Mary 6 -13.2455975 -4.889826
1 Anna 1 0.1428635 -11.981969
113 Emma 5 12.1987696 -1.243631
95 Elizabeth 4 -1.7484964 9.684795
74 Margaret 2 -4.7970545 -11.556546
2 Alice 1 -1.9868251 -10.067491Rather than using the default plot of the tsne package, I have plotted the data using ggplot2 in 2D space:
ggplot(namesdf, aes(x=x, y=y, color=factor(group), label=name)) +
geom_text(size=2) +
theme_classic() +
theme(legend.position='none')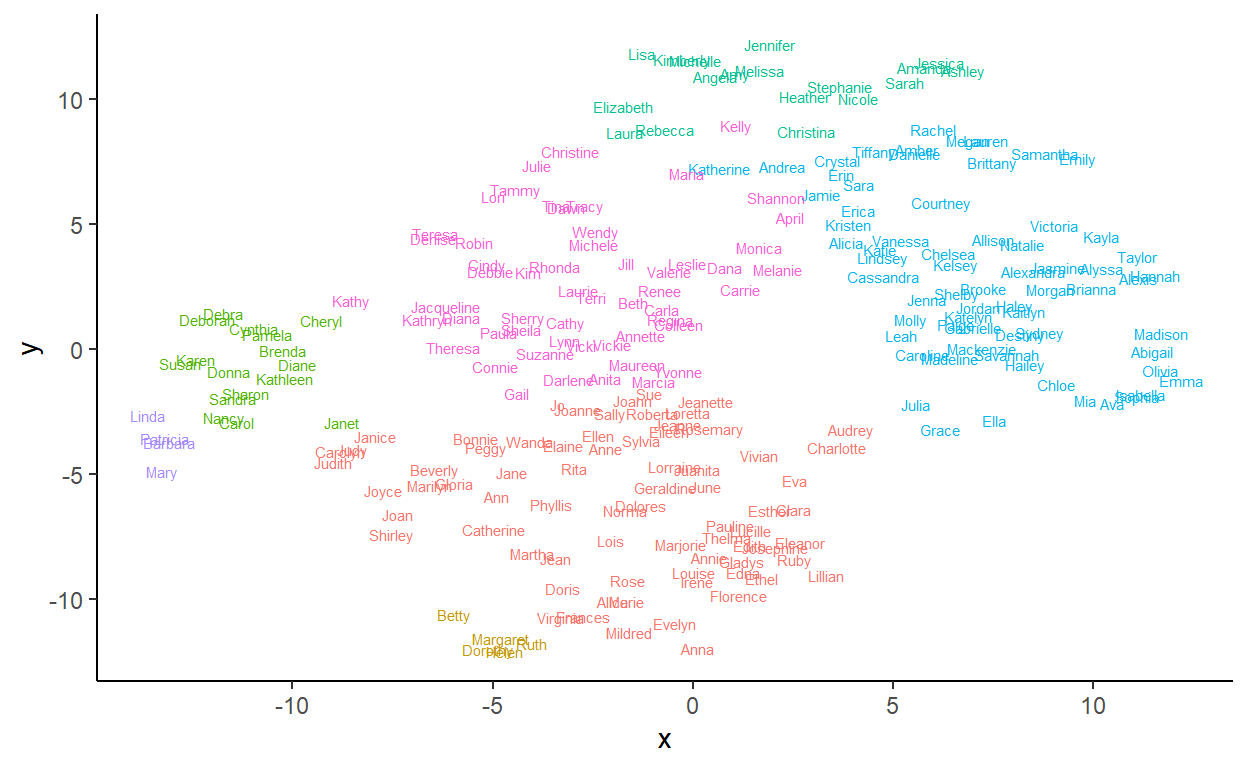
This is pretty cool. This data reduction and visualization method actually maps pretty well to what we did before. The different groups are denoted by different colors. Some logical patterns emerge.
The 1950s names - Barbara, Linda, Mary and Patricia are together in purple on the left hand side. Close by in lime green are the boomer names that were popular a little later. At the bottom in yellow are the names that were really popular in the 1920s (e.g. Dorothy, Helen).
The names that have become very popular recently (e.g. Isabella, Madison, Abigail) are on the far right side of visual space in light blue. Interestingly, Grace and Julia position next to each other with Ella not too far away - these are the names that were popular early and then have had a recent resurgence.
The names in green at the topare those such as Jennifer that were very popular in the late 70s and 80s. Significantly, Lisa and Kimberly are close to each other - this might be because their peaks were pre 1975. Julie is another with pre-1975 peaks, but that name is in a different cluster. The names in blue close to the green group are the names that blossomed in the 80s and 90s before more recently declining in popularity such as Megan and Lauren.
Finally, much could be done to look for further patterns in the red and pink groups, but that will have to wait for another time ! There is also much that can be done with the less common names - again, we’ll look at those another time.